> computer science students should be familiar with the standard f(x)=O(g(x)) notation
I have always thought that expressing it like that instead of f(x) ∈ O(g(x)) is very confusing. I understand the desire to apply arithmetic notation of summation to represent the factors, but "concluding" this notation with equality, when it's not an equality... Is grounds for confusion.
I think this is 3.1 (3.0 Pro with the RL improv of 3.0 Flash).
But they probably decided to market it as Deep Think because why not charge more for it.
Hi, author of the blog post here! Yes thank you for catching this awful typo, it's fixed now! I did write "4000 or 5000 IU of Vitamin D" everywhere else in the article -- main text, conclusion -- just my luck that the one place I mess up is right at the very start.
(Do not take 5000 mg, that's 200,000,000 IU. You'd have to chug dozens of bottles per day)
Colon Blow: "It would take over 30,000 bowls. [ a giant pyramid of cereal bowls shoots up from under the man, who yells in terror as it rises ] To eat that much oat bran, you’d have to eat ten bowls a day, every day for eight and a half years."
On the one hand I look at some tech lifecycles and feel everything moves so slow (cars, energy and train infrastructure etc..). And then I look at other stuff and I cannot phantom that someone who was born 100 years ago saw a TV (or media electronic screen) from conception to modern miracle. As someone in his 20s I can't imagine what I'll see in the next 80 years!
Unfortunately technological progress is not always exponential. An human landed on the moon 56 years ago and people back then thought space travel would be a routine thing today so it'll be interesting to see how things go
It's certainly not routine, but I'd say the privatization of the space industry that's unfolded over the last few decades is significant progress.
When I get depressed and look out at the world, I'm actually amazed at what I'm living through—the internet, space travel, electric and autonomous cars, smartphones. It's really amazing.
SpaceEx has made a ton of progress in space travel, granted it's not an ideal situation with it being a mega corp, but it moved a hell of a lot faster than NASA could have.
Perhaps someday we'll have individualized space flight like we have ownership over our cars and private planes.
Don't know what you're getting at by saying the galaxy will be ruled by mega-corps. Seems pretty democratic so far, and most of the things achieved couldn't have been without organization.
> As someone in his 20s I can't imagine what I'll see in the next 80 years!
All of these rapid technological advancements are a function of tremendous increases in energy available .
We passed peak conventional oil years ago and only see proven reserves increase because we redefined 'shale oil' as included under proven reserves. But shale oil has much lower EROEI than traditional oil. We can already see geopolitics heating up before our eyes to capture and control what remains, but to continue to advance society we need more energy.
On top of this we are just now starting to feel the impacts of the effects of the byproducts of this energy usage: climate change. What we are experiencing now is only a slight hint of what is to come in recent years.
In the next 80 years we'll very likely see an incredible decline in technology as certain complex systems no longer have adequate energy to maintain. The climate will continue to worsen and in more extreme ways, while geopolitics melts down in a struggle for the last bits of oil and fossil fuels (interestingly these combine in the fight for Greenland because a soon-to-be ice free arctic holds lots of oil, not enough to advance civilization the way it has been going, but enough to keep yours running if you can keep everyone else away).
I sincerely suspect within the next 80 years we will see the full collapse of industrial civilization and very possibly the near or complete extinction of the human race. You can see the early stages of this beginning to unfold right now.
I don't think we'll see a decline in technology globally but there will definitely be some regressions in countries that put feel good politics over the energy needs of their citizens.
I found this video on battery chemistry very interesting. Even if Donut claims about the batteries are not true, I still feel I learned quite a bit about batteries from this video. Of course, if they figured this out, a nobel of chemistry is probably in line.
We do have tech that is "behind doors". Just look at military applications (nuclear, tank and jet design etc). Should "clonable voice and video" be behind close doors? Or should AGI be behind close doors? I think that the approach of the suggested legistation may not the right way to go about; but at a certain level of implementation capability I'm not sure how I would handle this situation.
If current tech appeared all of a sudden in 1999; I am sure as a society we would all accept this, but slow boiling frog theory I guess.
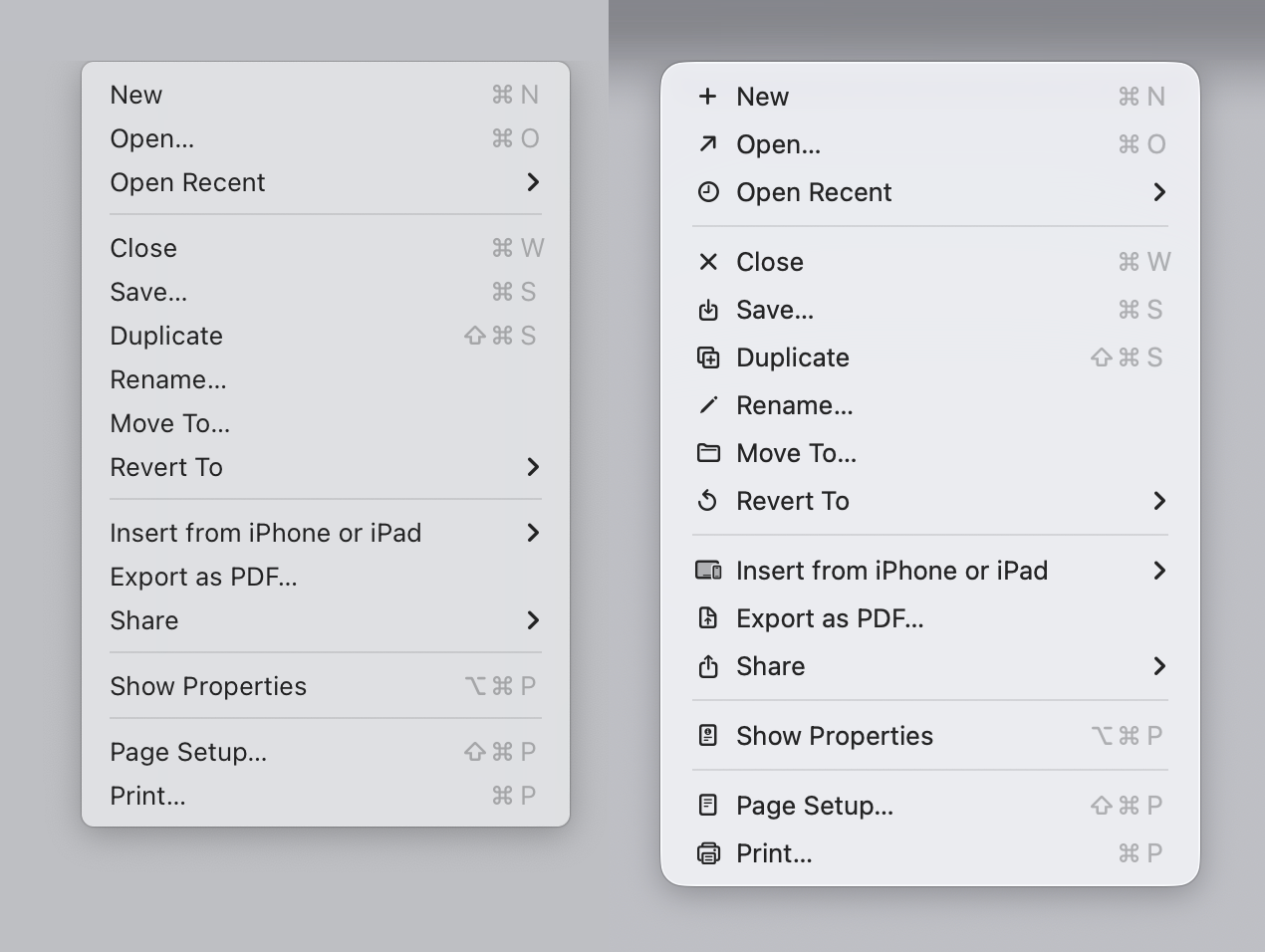
The article starts with this: > Sequoia → Tahoe It’s bad
And I look at the image... And I like it? I agree with the author that it could be better, but most of the icons (new, open recent, close, save, duplicate, print, share etc), do make it easier, faster and more pleasant for my brain to parse the menu vs no icons.
Again, I don't disagree that you could do it better, I just disagree with the premise that the 1992 manual is "the authority". Display density has increased dramatically; people use their computers more and have been accustomed to those interfaces, which makes the relationship of the people with the interfaces different. Quoting a 1992 guideline on interfaces in 2026 feels like quoting the greeks on philosophy while ignoring our understandings of the world since then.
Humans are definitely not the same as in 1992 when it comes to their everyday knowledge of computer interactions.
And even if human cognition itself were unchanged, our understanding of HCI has evolved significantly since then, well beyond what merely “feels right.”
Most UX researchers today can back up their claims with empirical data.
The article goes on at great length about consistency, yet then insists that text transformations require special treatment, with the HIG example looking outright unreadable.
Menu text should remain stable and not mirror or preview what’s happening to the selected text IMHO.
Also, some redundancy is not necessarily a bad thing in UI design, and not all users, for various reasons, can read with a vocabulary that covers the full breadth of what a system provides.
Most UX researchers today can back up their claims with empirical data.
HCI work in 1992 was very heavily based on user research, famously so at Apple. They definitely had the data.
I find myself questioning that today (like, have these horrible Tahoe icons really been tested properly?) although maybe unfairly, as I'm not an HCI expert. It does feel like there are more bad UIs around today, but that doesn't necessarily mean techniques have regressed. Computers just do a hell of a lot more stuff these days, so maybe it's just impossible to avoid additional complexity.
One thing that has definitely changed is the use of automated A/B testing -- is that the "empirical data" you're thinking of? I do wonder if that mostly provides short-term gains while gradually messing up the overall coherency of the UI.
Also, micro-optimizing via A/B testing can lead to frequent UI churn, which is something that I and many others find very annoying and confusing.
Tognazzini and Norman already criticized Appple about this a decade ago, while the have many good points, I cannot shake the feeling that they simply feel like the were used to just brand Apple as user friendly in the 90s and that Apple never actually adopted their principles and just used it as it fit the company's marketing.
Hmmm, I don't quite see where that supports "Apple didn't do empirical validation"? Is it just that it doesn't mention empirical validation at all, instead focusing on designer-imposed UI consistency?
ISTR hearing a lot about how the Mac team did user research back in the 1980s, though I don't have a citation handy. Specific aspects like the one-button mouse and the menu bar at the top of the screen were derived by watching users try out different variations.
I take that to be "empirical validation", but maybe you have a different / stricter meaning in mind?
Admittedly the Apple designers tried to extract general principles from the user studies (like "UI elements should look and behave consistently across different contexts") and then imposed those as top-down design rules. But it's hard to see how you could realistically test those principles. What's the optimal level of consistency vs inconsistency across an entire OS? And is anyone actually testing that sort of thing today?
I cannot shake the feeling that they simply feel like the were used to just brand Apple as user friendly in the 90s and that Apple never actually adopted their principles and just used it as it fit the company's marketing.
I personally think Apple did follow their own guidelines pretty closely in the 90s, but in the OS X era they've been gradually eroded. iOS 7 in particular was probably a big inflexion point -- I think that's when many formerly-crucial principles like borders around buttons were dropped.
The person I replied to said, "that interface designers or even the average computer user understands more than in 1992 is highly implausible on its face"
Think of computer users at the ages of 10, 20, 30, 40, 50, 60, 70, and 80 in 1992. For each group, estimate their computer knowledge when they sat down at a computer in 1992.
Now do the same exercise for the year 2026.
How is it highly implausible on its face that the average computer user in 2026 understands less than the average computer user in 1992?
> The person I replied to said, "that interface designers or even the average computer user understands more than in 1992 is highly implausible on its face"
Yes, I agree with this person.
>How is it highly implausible on its face that the average computer user in 2026 understands less than the average computer user in 1992?
I don't think it is. Particularly with the average user, the bar of understanding is lower now.
> Particularly with the average user, the bar of understanding is lower now.
Can you explain how this is true given that everyone using a computer today has had a lifetime of computer use whereas in 1992 many people were encountering computers for the first time?
1. Computer users were generally well-educated, unlike today.
2. UX designers didn’t inherit any mess and could operate from first principles.
3. The “experience” of modern users—phones, tablets, and software that does everything for you—doesn’t translate the way you think. And it explains why Gen Z seems to have regressed in terms of tech knowledge.
> Can you explain how this is true given that everyone using a computer today has had a lifetime of computer use whereas in 1992 many people were encountering computers for the first time?
The userbase has been watered down with a larger proportion of individuals who are not highly technical.
most of your points are refuted in the article. but I'll pick this one : "Display density has increased dramatically" Yes, it has, and Tahoe does not take advantage of this, infact the icons are smaller, and harder to read, using fewer pixels than windows icons of 25 years ago.
Yet, we can't refute that my subjective opinion evaluation of the opening image looks better (for me) , reads better (for me) and is easier (for me) to parse. Either I don't fit the general guidelines, or the general guidelines need a revision, that's my point overall.
But answer me this. You say "but most [but not all? - interesting] of the icons do make it easier, faster and more pleasant for my brain to parse the menu vs no icons."
How does a list of icons that are used inconsistently, duplicated, used in other places, sometimes used and sometimes not used, not to mention illegible, positioned inconsistently, go directly against the broad (reasoned) rules of the Apple HIG, help 'make it easier' as you say?
This is literally what half the article is explaining and you are just saying - no it's easier to not be able to tell an icon apart, and it's easier to have the icons sometimes be the same or move locations, be so small as to be illegible.
How many did you get when the menu text was removed ? I just don't believe it makes it easier. But who am I to argue against someones 'subjective opinion evaluation' I'm just a guy on the internet.
ps I assume by the opening image, you mean the first screenshot supplied by the author of the article - the Sequoia to Tahoe menu comparison, which he brilliantly posted below a shot of the HIG which literally is explaining the exact same thing and why not to do it the Tahoe way. That in it self is confusing.
It makes no sense why Apple chose to do that with Tahoe?
I'll add a general comment - one of the reasons I use Apple systems was they had the UI stuff nailed down. Stuff was consistent. It looked and behaved in proper ways. It felt like a properly designed, holistic approach to UI design. Lately it's just a mess. This article touch the surface of the issues. My current beef is this stupid 'class of window' that appears now and again which is half-way between a dialog and a window. Best place to see it is immediately after a screenshot - click the thumb that appears. This window type doesn't behave like any other window. Z-order, closing, focus, actions that occur when you click certain things, are all different and inconsistent. But it does look a little like IOS though.
> of the reasons I use Apple systems was they had the UI stuff nailed down (...) Lately it's just a mess
I have never daily driven an Apple device, so I can't comment on this; but from what I seen I do agree that Apple UI has not been as consistent lately.
> ps I assume by the opening image, you mean the first screenshot supplied by the author of the article
> How does a list of icons that are used inconsistently, duplicated, used in other places, sometimes used and sometimes not used, not to mention illegible, positioned inconsistently, go directly against the broad (reasoned) rules of the Apple HIG, help 'make it easier' as you say?
Sure! First of all, I'm only commenting on the FIRST image of the blog. There are no duplicated images in it. The icons appear consistently used in that image (maybe export to PDF looks a bit off, but this is a pattern that I have seen repeated on other apps, so I'm used to it). I'm not sure how the icons would look on the actual display, but they look alright on my 4K display as shown on the blog. I also can't comment on they being used "inconsistently" across other parts because I don't use Apple devices.
I'm making a very narrow claim: On the first image, if I compare the menu on the left, with the menu on the right, I prefer the menu on the right. I have tried to "find X" on a menu on the left and then repeat a similar exercise on the right; I am faster on the right and I am more confident on the right. My brain seems to be using the icons as a "fast lookup" and the text to verify the action.
Now, does this translate to all other menus? No! The "File" example he shows is super confusing.
Also, it's possible I would prefer the less cluttered version with less icons. But for me (all icons) > (no icons) on that specific example.
I have not put enough mental energy to agree with the author on all of his individual suggestions across the article, but they look overall fine on the individual examples he provides. I'm just find the first example... not particularly compelling.
> Well - that's just your --- opinion, man
Well... Yes. But unless we objectively measure how I use the computer, that's the best we have got to evaluate my preference.
All my classes on human-computer interaction and design has always been about "listen to your users".
We're also in benchmark saturation territory. I heard it speculated that Anthropic emphasizes benchmarks less in their publications because internally they don't care about them nearly as much as making a model that works well on the day-to-day
These models still consistently fail the only benchmark that matters: if I give you a task, can you complete it successfully without making shit up?
Thus far they all fail. Code outputs don’t run, or variables aren’t captured correctly, or hallucinations are stated as factual rather than suspect or “I don’t know.”
It’s 2000’s PC gaming all over again (“gotta game the benchmark!”).
I can confidently say that anecdotally you’re completely wrong, but I’ll also allow a very different definition of ‘simple’ and/or attempting to use an unpopular environment as a valid anecdotal counterpoint.
the problem with these arguments is there are data points to support both sides because both outcomes are possible
the real thing is are you or we getting an ROI and the answer is increasingly more yeses on more problems, this trend is not looking to plateau as we step up the complexity ladder to agentic system
I don't reach for AI until I'm solidly stuck and then use it mostly for inspiration, it has yet to happen that it directly pointed at a solution and I'm pretty good at writing prompts. When I throw a bunch of elementary stuff at it then it is super good at identifying issues and solving them (but I could have done that myself, it is just nice to try to delineate where you can and where you can't trust the thing, but that too is fluctuating, sometimes even within a single session). Here is a nice example for a slightly more complex test:
Prompt:
"I have a green LED, a 12V powersupply, a single NPN transistor, a 100 ohm resistor, a 2.7K resistor and an electrolytic capacitor of 220 micro farads. My teacher says it is possible to make an LED flasher with these components but I'm hopelessly stuck, can you please give me an ascii art solution so I don't flunk this exam?"
The 2.7 kΩ resistor charges the 220 µF capacitor from the 12 V supply.
The capacitor voltage rises slowly.
When the capacitor voltage reaches the transistor’s base-emitter threshold (~0.6–0.7 V), the transistor suddenly switches ON.
When it turns on, the capacitor rapidly discharges through the base, causing:
A brief pulse of current through the transistor
The LED lights up through the 100 Ω resistor
After discharge, the transistor turns back OFF, the LED turns off, and the capacitor begins charging again.
This repeats automatically → LED flasher."
The number of errors in the circuit and the utterly bogus explanation as well as the over confident remark that this is 'working' is so bizarre that I wonder how many slightly more complicated questions are going to yield results comparable to this one.
I am right now implementing an imagining pipeline using OpenCV and TypeScript.
I have never used OpenCV specifically before, and have little imaging experience too. What I do have though is a PhD in astrophysics/statistics so I am able to follow along the details easily.
Results are amazing. I am getting results in 2 days of work that would have taken me weeks earlier.
ChatGPT acts like a research partner. I give it images and it explains why current scoring functions fails and throws out new directions to go in.
Yes, my ideas are sometimes better. Sometimes ChatGPT has a better clue. It is like a human collegue more or less.
And if I want to try something, the code is usually bug free. So fast to just write code, try it, throw it away if I want to try another idea.
I think a) OpenCV probably has more training data than circuits? and b) I do not treat it as a desperate student with no knowlegde.
I expect to have to guide it.
There are several hundred messages back and forth.
It is more like two researchers working together with different skill sets complementing one another.
One of those skillsets being to turn a 20 message conversation into bugfree OpenCV code in 20 seconds.
No, it is not providing a perfect solution to all problems on first iteration. But it IS allowing me to both learn very quickly and build very quickly. Good enough for me..
That's a good use case, and I can easily imagine that you get good results from it because (1) it is for a domain that you are already familiar with and (2) you are able to check that the results that you are getting are correct and (3) the domain that you are leveraging (coding expertise) is one that chatgpt has ample input for.
Now imagine you are using it for a domain that you are not familiar with, or one for which you can't check the output or that chatgpt has little input for.
If either of those is true the output will be just as good looking and you would be in a much more difficult situation to make good use of it, but you might be tempted to use it anyway. A very large fraction of the use cases for these tools that I have come across professionally so far are of the latter variety, the minority of the former.
And taking all of the considerations into account:
- how sure are you that that code is bug free?
- Do you mean that it seems to work?
- Do you mean that it compiles?
- How broad is the range of inputs that you have given it to ascertain this?
- Have you had the code reviewed by a competent programmer (assuming code review is a requirement)?
- Does it pass a set of pre-defined tests (part of requirement analysis)?
- Is the code quality such that it is long term maintainable?
I have used Gemini for reading and solving electronic schematics exercises, and it's results were good enough for me. Roughly 50% of the exercises managed to solve correctly, 50% wrong. Simple R circuits.
One time it messed up the opposite polarity of two voltage sources in series, and instead of subtracting their voltages, it added them together, I pointed out the mistake and Gemini insisted that the voltage sources are not in opposite polarity.
Schematics in general are not AIs strongest point. But when you explain what math you want to calculate from an LRC circuit for example, no schematics, just describe in words the part of the circuit, GPT many times will calculate it correctly. It still makes mistakes here and there, always verify the calculation.
I think most people treat them like humans not computers, and I think that is actually a much more correct way to treat them. Not saying they are like humans, but certainly a lot more like humans than whatever you seem to be expecting in your posts.
Humans make errors all the time. That doesn't mean having colleagues is useless, does it?
An AI is a colleague that can code very very fast and has a very wide knowledge base and versatility. You may still know better than it in many cases and feel more experienced that in. Just like you might with your colleagues.
And it needs the same kind of support that humans need. Complex problem? Need to plan ahead first. Tricky logic? Need unit tests. Research grade problem? Need to discuss through the solution with someone else before jumping to code and get some feedback and iterate for 100 messages before we're ready to code. And so on.
There is also Mercury LLM, which computes the answer directly as a 2D text representation. I don't know if you are familiar with Mercury LLM, but you read correctly, 2D text output.
Mercury LLM might work better getting input as an ASCII diagram, or generating an output as an ASCII diagram, not sure if both input and output work 2D.
Plumbing/electrical/electronic schematics are pretty important for AIs to understand and assist us, but for the moment the success rate is pretty low. 50% success rate for simple problems is very low, 80-90% success rate for medium difficulty problems is where they start being really useful.
It's not really the quality of the diagramming that I am concerned with, it is the complete lack of understanding of electronics parts and their usual function. The diagramming is atrocious but I could live with it if the circuit were at least borderline correct. Extrapolating from this: if we use the electronics schematic as a proxy for the kind of world model these systems have then that world model has upside down lanterns and anti-gravity as commonplace elements. Three legged dogs mate with zebras and produce viable offspring and short circuiting transistors brings about entirely new physics.
it's hard for me to tell if the solution is correct or wrong because I've got next to no formal theoretical education in electronics and only the most basic 'pay attention to polarity of electrolytic capacitors' practical knowledge, but given how these things work you might get much better results when asking it to generate a spice netlist first (or instead).
I wouldn't trust it with 2d ascii art diagrams, there isn't enough focus on these in the training data is my guess - a typical jagged frontier experience.
I have this mental model of LLMs and their capabilities, formed after months of way too much coding with CC and Codex, with 4 recursive problem categories:
1. Problems that have been solved before have their solution easily repeated (some will say, parroted/stolen), even with naming differences.
2. Problems that need only mild amalgamation of previous work are also solved by drawing on training data only, but hallucinations are frequent (as low probability tokens, but as consumers we don’t see the p values).
3. Problems that need little simulation can be simulated with the text as scratchpad. If evaluation criteria are not in training data -> hallucination.
4. Problems that need more than a little simulation have to either be solved by adhoc written code, or will result in hallucination. The code written to simulate is again a fractal of problems 1-4.
Phrased differently, sub problem solutions must be in the training data or it won’t work; and combining sub problem solutions must be either again in training data, or brute forcing + success condition is needed, with code being the tool to brute force.
I _think_ that the SOTA models are trained to categorize the problem at hand, because sometimes they answer immediately (1&2), enable thinking mode (3), or write Python code (4).
My experience with CC and Codex has been that I must steer it away from categories 2 & 3 all the time, either solving them myself, ask them to use web research, or split them up until they are (1) problems.
Of course, for many problems you’ll only know the category once you’ve seen the output, and you need to be able to verify the output.
I suspect that if you gave Claude/Codex access to a circuit simulator, it will successfully brute force the solution. And future models might be capable enough to write their own simulator adhoc (ofc the simulator code might recursively fall into category 2 or 3 somewhere and fail miserably). But without strong verification I wouldn’t put any trust in the outcome.
With code, we do have the compiler, tests, observed behavior, and a strong training data set with many correct implementations of small atomic problems. That’s a lot of out of the box verification to correct hallucinations. I view them as messy code generators I have to clean up after. They do save a ton of coding work after or while I‘m doing the other parts of programming.
This parallels my own experience so far, the problem for me is that (1) and (2) I can quickly and easily do myself and I'll do it in a way that respects the original author's copyright by including their work - and license - verbatim.
(3) and (4) level problems are the ones where I struggle tremendously to make any headway even without AI, usually this requires the learning of new domain knowledge and exploratory code (currently: sensor fusion) and these tools will just generate very plausible nonsense which is more of a time waster than a productivity aid. My middle-of-the-road solution is to get as far as I can by reading about the problem so I am at least able to define it properly and to define test cases and useful ranges for inputs and so on, then to write a high level overview document about what I want to achieve and what the big moving parts are and then only to resort to using AI tools to get me unstuck or to serve as a knowledge reservoir for gaps in domain knowledge.
Anybody that is using the output of these tools to produce work that they do not sufficiently understand is going to see a massive gain in productivity, but the underlying issues will only surface a long way down the line.
Sometimes you do need to (as a human) break down a complex thing into smaller simple things, and then ask the LLM to do those simple things. I find it still saves some time.
Or what will often work is having the LLM break it down into simpler steps and then running them 1 by 1. They know how to break down problems fairly well they just don't often do it properly sometimes unless you explicitly prompt them to.
I'm not sure, here's my anecdotal counter example, was able to get gemini-2.5-flash, in two turns, to understand and implement something I had done separately first, and it found another bug (also that I had fixed, but forgot was in this path)
That I was able to have a flash model replicate the same solution I had, to two problems in two turns, it's just the opposite experience of your consistency argument. I'm using tasks I've already solved as the evals while developing my custom agentic setup (prompts/tools/envs). They are able to do more of them today then they were even 6-12 months ago (pre-thinking models).
And therein lies the rub for why I still approach this technology with caution, rather than charge in full steam ahead: variable outputs based on immensely variable inputs.
I read stories like yours all the time, and it encourages me to keep trying LLMs from almost all the major vendors (Google being a noteworthy exception while I try and get off their platform). I want to see the magic others see, but when my IT-brain starts digging in the guts of these things, I’m always disappointed at how unstructured and random they ultimately are.
Getting back to the benchmark angle though, we’re firmly in the era of benchmark gaming - hence my quip about these things failing “the only benchmark that matters.” I meant for that to be interpreted along the lines of, “trust your own results rather than a spreadsheet matrix of other published benchmarks”, but I clearly missed the mark in making that clear. That’s on me.
I mean more the guts of the agentic systems. Prompts, tool design, state and session management, agent transfer and escalation. I come from devops and backend dev, so getting in at this level, where LLMs are tasked and composed, is more interesting.
If you are only using provider LLM experiences, and not something specific to coding like copilot or Claude code, that would be the first step to getting the magic as you say. It is also not instant. It takes time to learn any new tech, this one has a above average learning curve, despite the facade and hype of how it should just be magic
Once you find the stupid shit in the vendor coding agents, like all us it/devops folks do eventually, you can go a level down and build on something like the ADK to bring your expertise and experience to the building blocks.
For example, I am now implementing environments for agents based on container layers and Dagger, which unlocks the ability to cheaply and reproducible clone what one agent was doing and have a dozen variations iterate on the next turn. Real useful for long term training data and evals synth, but also for my own experimentation as I learn how to get better at using these things. Another thing I did was change how filesystem operations look to the agent, in particular file reads. I did this to save context & money (finops), after burning $5 in 60s because of an error in my tool implementation. Instead of having them as message contents, they are now injected into the system prompt. Doing so made it trivial to add a key/val "cache" for the fun of it, since I could now inject things into the system prompt and let the agent have some control over that process through tools. Boy has that been interesting and opened up some research questions in my mind
Any particular papers or articles you've been reading that helped you devise this? Your experiments sound interesting and possibly relevant to what I'm doing.
Building a good model generally means it will do well on benchmarks too. The point of the speculation is that Anthropic is not focused on benchmaxxing which is why they have models people like to use for their day-to-day.
I use Gemini, Anthropic stole $50 from me (expired and kept my prepaid credits) and I have not forgiven them yet for it, but people rave about claude for coding so I may try the model again through Vertex Ai...
The person who made the speculation I believe was more talking about blog posts and media statements than model cards. Most ai announcements come with benchmark touting, Anthropic supposedly does less / little of this in their announcements. I haven't seen or gathered the data to know what is truth
How would published numbers be useful without knowing what the underlying data being used to test and evaluate them are? They are proprietary for a reason
To think that Anthropic is not being intentional and quantitative in their model building, because they care less for the saturated benchmaxxing, is to miss the forest for the trees
I'd recommend watching Nathan Lambert's video he dropped yesterday on Olmo 3 Thinking. You'll learn there's a lot of places where even descriptions of proprietary testing regimes would give away some secret sauce
Nathan is at Ai2 which is all about open sourcing the process, experience, and learnings along the way
Thanks for the reference I'll check it out. But it doesnt really take away from the point I am making. If a level of description would give away proprietary information, then go one level up to a more vague description. How to describe things to a proper level is more of a social problem than a technical one.
You seem stuck on the idea that they should have to share information when they don't have to. That they share any is a welcome change. Push too hard and they may stop sharing as much
Ah yes, humans are famously empirical in their behavior and we definitely do not have direct evidence of the "best" sports players being much more likely than the average to be superstitious or do things like wear "lucky underwear" or buy right into scam bracelets that "give you more balance" using a holographic sticker.
if you think about GANs, it's all the same concept
1. train model (agent)
2. train another model (agent) to do something interesting with/to the main model
3. gain new capabilities
4. iterate
You can use a mix of both real and synthetic chat sessions or whatever you want your model to be good at. Mid/late training seems to be where you start crafting personality and expertises.
Getting into the guts of agentic systems has me believing we have quite a bit of runway for iteration here, especially as we move beyond single model / LLM training. I still need to get into what all is de jour in the RL / late training, that's where a lot of opportunity lies from my understanding so far
It is very similar to an IQ test, with all the attendant problems that entails. Looking at the Arc-AGI problems, it seems like visual/spatial reasoning is just about the only thing they are testing.
Completely false. This is like saying being good at chess is equivalent to being smart.
Look no farther than the hodgepodge of independent teams running cheaper models (and no doubt thousands of their own puzzles, many of which surely overlap with the private set) that somehow keep up with SotA, to see how impactful proper practice can be.
The benchmark isn’t particularly strong against gaming, especially with private data.
ARC-AGI was designed specifically for evaluating deeper reasoning in LLMs, including being resistant to LLMs 'training to the test'. If you read Francois' papers, he's well aware of the challenge and has done valuable work toward this goal.
I agree with you. I agree it's valuable work. I totally disagree with their claim.
A better analogy is: someone who's never taken the AIME might think "there are an infinite number of math problems", but in actuality there are a relatively small, enumerable number of techniques that are used repeatedly on virtually all problems. That's not to take away from the AIME, which is quite difficult -- but not infinite.
Similarly, ARC-AGI is much more bounded than they seem to think. It correlates with intelligence, but doesn't imply it.
> but in actuality there are a relatively small, enumerable number of techniques that are used repeatedly on virtually all problems
IMO/AIME problems perhaps, but surely that's too narrow a view for all of mathematics. If solving conjectures were simply a matter of trying a standard range of techniques enough times, then there would be a lot fewer open problems around than what's the case.
Maybe I'm misinterpreting your point, but this makes it seem that your standard for "intelligence" is "inventing entirely new techniques"? If so, it's a bit extreme, because to a first approximation, all problem solving is combining and applying existing techniques in novel ways to new situations.
At the point that you are inventing entirely new techniques, you are usually doing groundbreaking work. Even groundbreaking work in one field is often inspired by techniques from other fields. In the limit, discovering truly new techniques often requires discovering new principles of reality to exploit, i.e. research.
As you can imagine, this is very difficult and hence rather uncommon, typically only accomplished by a handful of people in any given discipline, i.e way above the standards of the general population.
I feel like if we are holding AI to those standards, we are talking about not just AGI, but artificial super-intelligence.
Took a couple just now. It seems like a straight-forward generalization of the IQ tests I've taken before, reformatted into an explicit grid to be a little bit friendlier to machines.
Not to humble-brag, but I also outperform on IQ tests well beyond my actual intelligence, because "find the pattern" is fun for me and I'm relatively good at visual-spatial logic. I don't find their ability to measure 'intelligence' very compelling.
Given your intellectual resources -- which you've successfully used to pass a test that is designed to be easy for humans to pass while tripping up AI models -- why not use them to suggest a better test? The people who came up with Arc-AGI were not actually morons, but I'm sure there's room for improvement.
What would be an example of a test for machine intelligence that you would accept? I've already suggested one (namely, making up more of these sorts of tests) but it'd be good to get some additional opinions.
With this kind of thing, the tails ALWAYS come apart, in the end. They come apart later for more robust tests, but "later" isn't "never", far from it.
Having a high IQ helps a lot in chess. But there's a considerable "non-IQ" component in chess too.
Let's assume "all metrics are perfect" for now. Then, when you score people by "chess performance"? You wouldn't see the people with the highest intelligence ever at the top. You'd get people with pretty high intelligence, but extremely, hilariously strong chess-specific skills. The tails came apart.
Same goes for things like ARC-AGI and ARC-AGI-2. It's an interesting metric (isomorphic to the progressive matrix test? usable for measuring human IQ perhaps?), but no metric is perfect - and ARC-AGI is biased heavily towards spatial reasoning specifically.
The models never have access to the answers for the private set -- again, at least in principle. Whether that's actually true, I have no idea.
The idea behind Arc-AGI is that you can train all you want on the answers, because knowing the solution to one problem isn't helpful on the others.
In fact, the way the test works is that the model is given several examples of worked solutions for each problem class, and is then required to infer the underlying rule(s) needed to solve a different instance of the same type of problem.
That's why comparing Arc-AGI to chess or other benchmaxxing exercises is completely off base.
(IMO, an even better test for AGI would be "Make up some original Arc-AGI problems.")
It's very much a vision test. The reason all the models don't pass it easily is only because of the vision component. It doesn't have much to do with reasoning at all
Imagine that pattern recognition is 10% of the problem, and we just don't know what the other 90% is yet.
Streetlight effect for "what is intelligence" leads to all the things that LLMs are now demonstrably good at… and yet, the LLMs are somehow missing a lot of stuff and we have to keep inventing new street lights to search underneath: https://en.wikipedia.org/wiki/Streetlight_effect
I dont think many people are saying 100% arc-agi 2 is equivalent to AGI(names are dumb as usual). Its just the best metric I have found, not the final answer. Spatial reasoning is an important part of intelligence even if it doesnt encompass all of it.
> It'll be noteworthy to see the cost-per-task on ARC AGI v2.
Already live. gpt-5.2-pro scores a new high of 54.2% with a cost/task of $15.72. The previous best was Gemini 3 Pro (54% with a cost/task of $30.57).
The best bang-for-your-buck is the new xhigh on gpt-5.2, which is 52.9% for $1.90, a big improvement on the previous best in this category which was Opus 4.5 (37.6% for $2.40).
That ARC AGI score is a little suspicious. That's a really tough for AI benchmark. Curious if there were improvements to the test harness because that's a wild jump in general problem solving ability for an incremental update.
They're clearly building better training datasets and doing extensive RL on these benchmarks over time. The out of distribution performance is still awful.
Open AI has already been busted for getting benchmark information and training the models on that. At this point if you believe Sam Altman, I have a bridge to sell you.
Model capability improvements are very uneven. Changes between one model and the next tend to benefit certain areas substantially without moving the needle on others. You see this across all frontier labs’ model releases. Also the version numbering is BS (remember GPT-4.5 followed by GPT-4.1?).
{kind=link}
I have always thought that expressing it like that instead of f(x) ∈ O(g(x)) is very confusing. I understand the desire to apply arithmetic notation of summation to represent the factors, but "concluding" this notation with equality, when it's not an equality... Is grounds for confusion.
reply